Understanding market dynamics to data-led business decisions

As machine learning establishes its place in the global economy and data falls into a more strategic role, it’s crucial to understand the ways in which data-led decision making can stem from meaningful recommendations.
Thus, the following blog post is written for anyone intrigued by data and leading-edge data strategy, which provide industry and product-agnostic applications.
Whether you operate within the automotive industry or in another sphere of business, lessons drawn from our application of data science are transferable to any business interested in leveraging their data.
Understanding your market dynamics
To drive continuous progression of your marketplace, it’s important to pay attention to both transactional and behavioural data which stem from business operations. For any organisation, understanding user journeys on a multi-sided trading platform is a process which requires intelligent filtering and segmentation of data.
Beyond collecting the right data, it’s crucial to have KPIs in place that reflect the ultimate business goals as analysing data is a continuous never-ending process. There should be validity checkpoints at which you stop and say: “What does this trend or output mean, and how does it impact my end goal or view on the marketplace?”
Measuring marketplace performance is key to growth, long-term sustainability and value optimisation. Why? To ensure that all segments of the market are thick (attracting the optimal number of both sell-side and buy-side participants) and functioning efficiently. Without such a measure of success, it will be difficult to pinpoint why your market isn’t operating to the same degree as your competitors, or others in tangential areas of business.
Below is a breakdown of framework on how we propose tackling the first step in the process of data analysis and understanding what’s happening in your market. Developing a universal view of your marketplace stems from understand of your (1) trading model and (2) users to understand how these factors affect overall success.
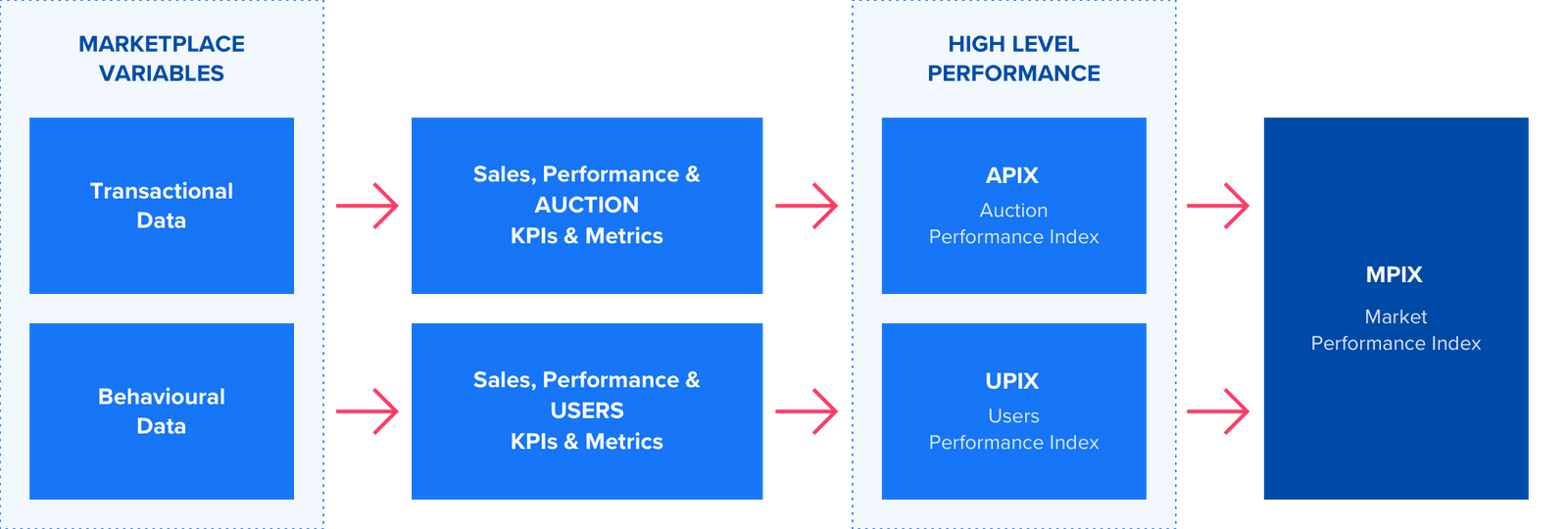
Identifying the right marketplace variables
When undertaking any project within the realm of data, the first step is defining the problem and the most appropriate data to collect to help identify the solution. And while machine learning models and recommendation engines are the ultimate goals, we couldn’t get there without doing the due diligence, in the form of quality control.
To achieve this aim, data is analysed and managed on various dimensions. Without getting into technicalities such as security and representation, it’s essential to first determine the contextual scope in which the data is relevant for the task at hand and then assess the intrinsic quality of it. After all, in order to reach reliable outcomes, you must have reliable data.
Contingent on the nature of the problem you are looking to solve, (a) operational (transactional), (b) behavioural or (c) a combination of both types of data might be required.
Once you have identified the relevant data sources, it’s important to evaluate how ‘good’ their quality is. Mechanisms to measure the accuracy and objectivity of data are helpful in this regard, as well as processes to assess data source completeness and volume. Depending on your objective, it may be necessary to ensure statistical significance of results. Subject to the statistical test and desired outcome of analysis, a minimum sample size is necessary to ensure confidence your answer or outcome is ‘real’, allowing you to be empowered by the decision you reach.
A large part of the process previously described requires setting parameters around the scope of your project, evaluating historical data reliability as well as revising the process of how data is collected, highlighting any potential risks outright. Risk identification is a crucial step in the path to success in understanding the consistency of the data.
What exactly does this mean? For instance, in an automotive context, securing proper standards for attributes such as fuel type, transmission, mileage, wheel drive, etc. are crucial for reliable streamlined comparisons of the vehicles. While attributes that are less relevant in the decision process like interior colour or fiscal (tax) horsepower require less strict rules, they might just help to discriminate a small non-significant behaviour. In other words, the interior colour for example is less relevant in the consumer decision process. In the context of vehicle re-selling, very few buyers really care about the colour of the vehicle, so having “less” strict rules will not harm the overall recommendation/prediction because their contribution is very small.
To provide further background, a “usability” process is recommended to check inconsistencies for relevant and non-relevant attributes. If most of the inconsistencies are concentrated across a number of data sources, it is easier to take immediate corrective action and align the data governance framework accordingly. The result? An efficient Data Quality control process that proactively identifies potential risks that could be spread across the data collection and set correction mechanisms accordingly.
The aim in this process is to land on a data set which you are confident will empower your algorithms to make valid recommendations. At the end of the day, the heart of any recommendation engine is its algorithm, with data acting as the fuel driving the system.
The good news is that extensions of this process can apply to any industry looking to reduce quality issues and improve the relevancy of analysis.
Product recommendations
Product recommendation functionality is an integral part of optimising the performance of your platform as the B2C world has grown accustomed to buyer-personalised experiences online. As the B2B market catches on, we’ve developed an algorithm which learns buyer preferences from historical bid event-data and mines all available live listings on a given platform for those matching buyer preferences.
As a result, recommended listings with the strongest relevance are presented on a buyer’s dashboard. Beyond this capability, it’s key to pay attention to what we call ‘reasonable alternatives’ as well. This is an algorithm which learns what buyers collectively regard as similar (substitute) product types to provide additional recommendations to fill demand.
Auction format recommendation model
Over the last 5 years, we have developed our data science strategy, including a predictive model to ascertain the most appropriate auction model on a per product (per vehicle) basis.
Milestones include:
- Clustering analysis: Identify segments of vehicles and entities that share similar characteristics.
- Use case model: Identify the best candidates, or the most representative instances, to develop a model. It’s essential to include a ”good” distribution of auction types across several periods.
- Modelling and continuous improvement: Define the model that better suits the market conditions and define key metrics to monitor its performance so it can be iteratively improved.
The resulting prediction model is one that recommends the auction format with the highest likelihood of “success” given a vehicle. In an applied scenario, each selected vehicle would have a real time recommendation on the best auction format according to its characteristics.
In the example below, you can see from illustrative figures how bids within corresponding auction models can be compared to determine the optimal format for listing products on a marketplace. By increasing the probability of sale, the market has the ability to clear more quickly and efficiently.
Case study example: CarNext
Background – NovaFori solution
NovaFori deployed its recommendation engine to CarNext’s B2B marketplace.
The engine first recommends vehicles to users based on previous buyer behaviour. The recommendation is then refined based on user actions on the platform in the form of searches, bids, substitutions and won lots, resulting in automated alerts sent to potential buyers via mobile.
The result
Vehicles recommended via NovaFori’s recommendation engine have accounted for up to 12% of vehicles sold on CarNext on a monthly basis, with a significant increase observed in average sale prices. To provide an example, based on vehicle attributes such as make, model, horsepower, etc., our recommendation engine can suggest a different auction or trade format preferable to the original model. A vehicle may have a 50% probability of sale under a sealed bid model, but a 99% probability of sale if an open bid model is used.
What does this mean beyond the automotive application?
In order to foster continuous calibration of user preferences and increase the ‘stickiness’ of marketplaces, industries ranging from fine art to commodities and financial services can benefit from the implementation of data science and fine-tuned recommendation engines. The e-commerce industry was obviously the first to widely adopt recommendation systems and therefore provides the greatest use case in the B2B world for translation of solution.
However, thinking more in depth about sectors which operate in a largely manual fashion when it comes to selling and procurement, companies operating within logistics and commodities would benefit from knowledge on the optimal auction and trading models by product type.
Additionally, these industries involve products and solutions with a multitude of attributes to analyse. What does this mean? The engine can continuously monitor user behaviour across multiple products, learning which attributes (tonnage, speed, fuel type, current location in the shipping industry for example) are common across such products, to make more intelligent recommendations to end users. As a result, users will be drawn to doing business on a platform which understands their desires, rather than elsewhere.
If you’d like to learn more, contact us to find out how our data science expertise can augment your business model and increase your margins. We are experts in building intelligent marketplaces, attuned to your needs.
Sign up
Subscribe to receive our blogs, white papers and media articles.